
Z-Ordering in Apache Spark
Z-Ordering is a technique used in Apache Spark to optimize the performance of queries, particularly for large datasets. It is part of Delta Lake, a storage layer built on top of Apache Spark, and is used to improve query performance by clustering data based on specific columns. This technique is highly useful in scenarios where certain queries frequently filter or join on specific columns, helping to reduce the amount of data that Spark needs to scan.
 What is Z-Ordering?
What is Z-Ordering?
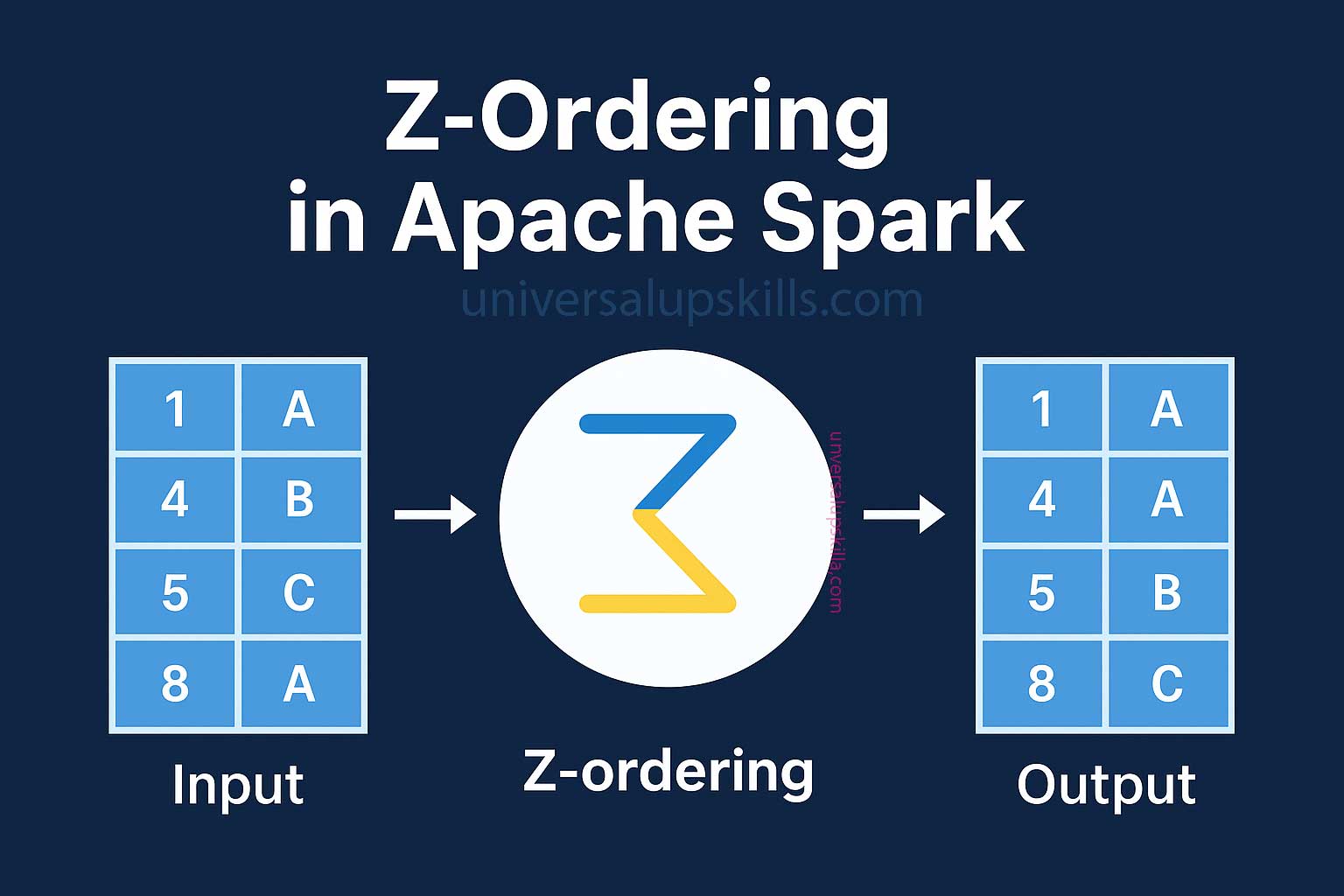
Z-Ordering is a method of reorganizing the data into multi-dimensional clusters based on a set of columns, allowing data with similar values in those columns to be physically co-located on disk. This minimizes the amount of data read during queries, especially when there are range filters or equality filters on those columns.
In simple terms, Z-Ordering helps to store data in a way that optimizes read operations for specific queries that filter or join on those columns, reducing I/O and speeding up query performance.
How Z-Ordering Works
- Multi-Dimensional Clustering: Z-Ordering works by sorting data in a multi-dimensional space based on the selected columns. For example, if you choose columns
AandB, Spark organizes the data to group rows with similar values in both columns together. - Z-Order Curve: The Z-ordering technique uses a Z-curve (a space-filling curve) to map multi-dimensional data (like two columns) into a one-dimensional ordering. This curve ensures that data with similar values in both dimensions is close to each other on disk.
- Z-Ordering Columns: You can specify one or more columns for Z-Ordering. Spark will reorganize the data on disk so that rows with similar values in those columns are physically close together.
Why Use Z-Ordering?
Z-Ordering is especially useful when:
- You have large datasets that are frequently queried with filters on specific columns.
- You frequently perform range-based queries or joins on certain columns.
- You want to optimize query performance without needing to repartition or reindex the data manually.
When used in combination with Delta Lake, Z-Ordering can help minimize the data that Spark needs to scan, leading to faster queries.
When to Apply Z-Ordering
- When Performing Range Queries: Z-Ordering is beneficial for queries with range filters (e.g.,
BETWEENor>=/<=) on columns, as it helps Spark skip irrelevant data. - When Performing Joins: If joins are frequently done on certain columns, Z-Ordering the data by those columns can reduce the number of shuffle operations and improve join performance.
- For Time-based or Event-based Data: If you have time-series or event-based data where queries filter based on date or time, applying Z-Ordering on the timestamp column can speed up filtering by time.
- When Writing Data: If you’re writing data to Delta Lake (e.g., after an ETL process), it might be beneficial to use Z-Ordering after the write operation to optimize it for future queries.
How to Apply Z-Ordering in Spark (Delta Lake)
In Delta Lake, you can apply Z-Ordering using the OPTIMIZE command. The OPTIMIZE command helps to compact small files into larger ones and reorder the data based on the specified columns.
Here is an example of applying Z-Ordering in Spark using Delta Lake:
# Import necessary libraries
from delta.tables import DeltaTable
# Define the Delta table path
delta_table_path = "/path/to/delta-table"
# Apply Z-Ordering on specific columns (e.g., "column1", "column2")
spark.sql(f"OPTIMIZE delta.`{delta_table_path}` ZORDER BY (column1, column2)")
Key Steps in Z-Ordering with Delta Lake:
- Load Data: First, ensure the data is stored in a Delta table format.
- Optimize: Use the
OPTIMIZEcommand with theZORDER BYclause, specifying the columns on which you want to apply Z-Ordering. - Query Performance: After applying Z-Ordering, future queries that filter or join on the specified columns should benefit from improved performance.
Best Practices for Z-Ordering
- Select Columns Carefully: Z-Ordering should be applied to columns that are frequently queried for filtering or joining. Applying Z-Ordering on non-relevant columns may not provide a significant performance boost.
- Avoid Overusing Z-Ordering: Z-Ordering requires additional storage and computational overhead during the optimization process. Only apply Z-Ordering on columns that genuinely benefit your most common query patterns.
- Optimize After Significant Updates: If your Delta Lake table has undergone significant updates (e.g., lots of inserts, updates, or deletes), applying
OPTIMIZEwith Z-Ordering can help improve query performance by compacting small files and reordering the data. - Use in Combination with Partitioning: Z-Ordering works well in combination with partitioning, especially if your data is partitioned by columns that are not frequently queried. Z-Ordering helps optimize the layout of data within partitions.
Limitations of Z-Ordering
- No Magic Bullet: While Z-Ordering improves query performance for specific use cases, it may not always lead to drastic improvements. Its effectiveness depends on how the data is queried.
- Storage Overhead: Reordering the data through Z-Ordering can introduce storage overhead. It requires additional processing time when performing the optimization, and this may increase the overall storage cost.
- Not a Substitute for Partitioning: Z-Ordering is complementary to partitioning, but it doesn’t replace partitioning. Partitioning should still be used for large-scale datasets, especially for time-based or range-based queries.
Summary
Z-Ordering in Apache Spark (via Delta Lake) is a technique to optimize the physical layout of data by clustering rows with similar values on specific columns. It improves query performance by reducing the amount of data that needs to be scanned when filtering or joining on those columns. Applying Z-Ordering can be highly beneficial for large datasets with common filtering or joining patterns. However, it is important to use Z-Ordering strategically to avoid unnecessary overhead.
