
Loading data from an on-premises data source to Azure Data Lake Storage (ADLS) using Azure Data Factory (ADF) involves the following steps. The key component for connecting on-premises data sources is the Self-Hosted Integration Runtime (SHIR).
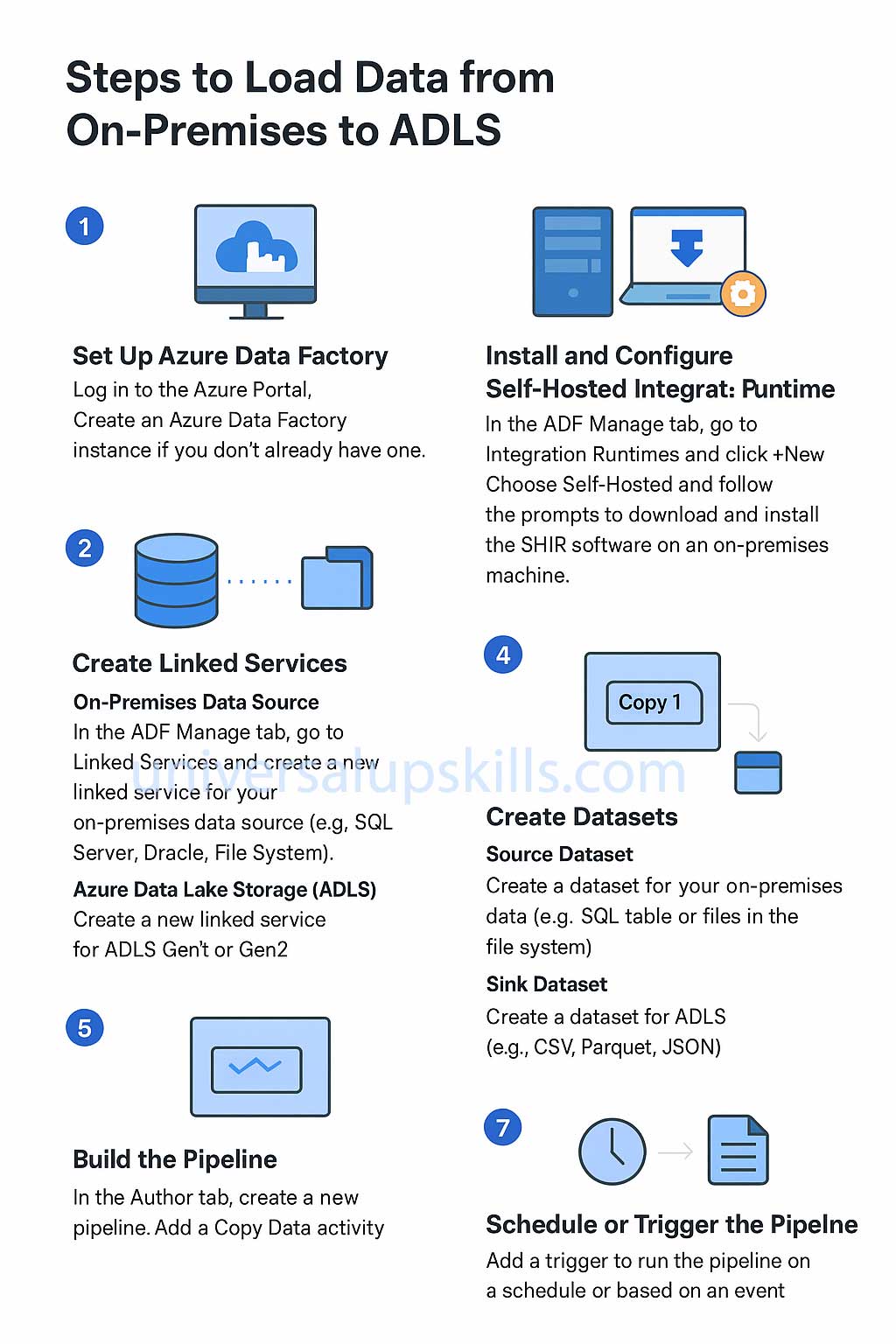
Steps to
Load Data from On-Premises to ADLS
1. Set Up Azure Data Factory
- Log in to the Azure Portal.
- Create an Azure Data Factory instance if you don’t already have one.
2. Install and Configure the Self-Hosted Integration Runtime
The SHIR enables ADF to access on-premises data sources securely.
- In the ADF Manage tab, go to Integration Runtimes and click + New.
- Choose Self-Hosted and follow the prompts to download and install the SHIR software on an on-premises machine.
- During installation:
- Copy the authentication key from ADF and paste it into the SHIR setup wizard.
- Configure the SHIR to run under an account with access to the on-premises data.
- Once installed, ensure the SHIR status shows as Online in ADF.
3. Create Linked Services
Linked Services define the connections to your data sources and sinks.
- On-Premises Data Source:
- In the ADF Manage tab, go to Linked Services and create a new linked service for your on-premises data source (e.g., SQL Server, Oracle, File System).
- Choose the corresponding connector, e.g., Azure SQL Server or File System, and configure:
- Server Name (for databases).
- Authentication: Provide credentials.
- Integration Runtime: Select the Self-Hosted Integration Runtime.
- Azure Data Lake Storage (ADLS):
- Create a new linked service for ADLS Gen1 or Gen2.
- Provide the Storage Account Name and select the appropriate authentication method (e.g., Managed Identity, Service Principal).
4. Create Datasets
Datasets represent the data structure of the source and sink.
- Source Dataset:
- Create a dataset for your on-premises data (e.g., SQL table or files in the file system).
- Point it to the linked service for your on-premises data source.
- Sink Dataset:
- Create a dataset for ADLS (e.g., CSV, Parquet, JSON).
- Point it to the linked service for ADLS.
5. Build the Pipeline
- In the Author tab, create a new pipeline.
- Add a Copy Data activity:
- Source:
- Select the on-premises dataset.
- Optionally, specify filters or query parameters for databases.
- Sink:
- Select the ADLS dataset.
- Configure file format settings (e.g., delimiter for CSV, folder structure).
- Source:
- (Optional) Add transformations or mappings as needed.
6. Test the Pipeline
- Debug the pipeline to test the data transfer.
- Check the Monitor tab to verify successful execution or troubleshoot errors.
7. Schedule or Trigger the Pipeline
- Add a trigger to run the pipeline on a schedule or based on an event.
Considerations
- Firewall Rules:
- Ensure that the on-premises machine running the SHIR can access the internet.
- Add firewall rules in Azure to allow SHIR communication.
- Authentication:
- Use a Service Principal or Managed Identity for secure access to ADLS.
- Performance:
- Optimize batch sizes and concurrency settings for large data transfers.
- Use compression (e.g., gzip) for faster uploads.
- Monitoring:
- Monitor data movement in the ADF Monitor tab.
- Check SHIR performance logs if the connection fails.
