
Understanding Delta Lake, Delta Table, and Delta Live Table in Databricks
Databricks offers a suite of tools for managing and analyzing data efficiently, with Delta Lake, Delta Table, and Delta Live Table being core components. Here’s a breakdown of their definitions, purposes, and differences:
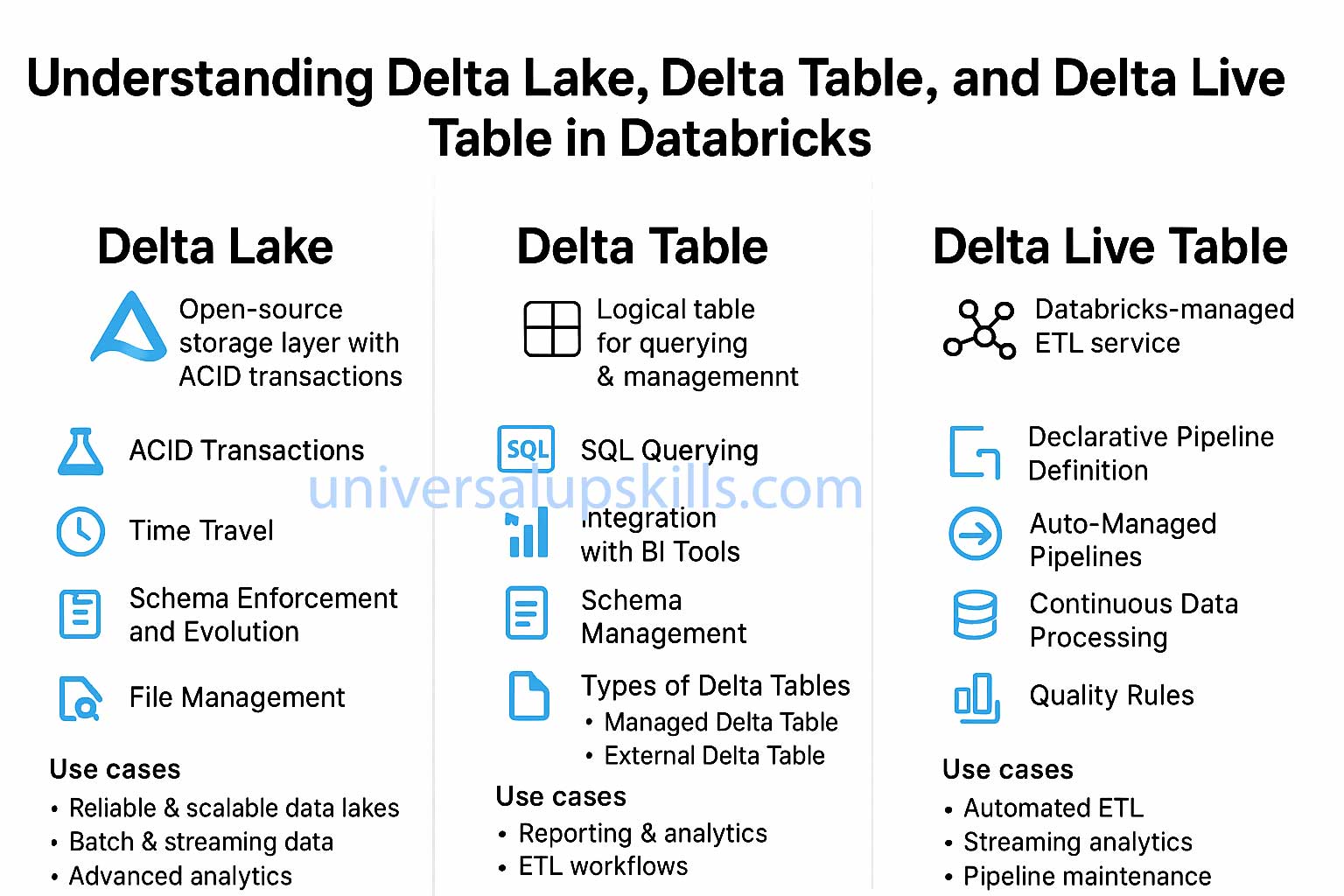
1. Delta Lake
Definition
Delta Lake is an open-source storage layer that brings ACID transactions, schema enforcement, time travel, and unified batch and streaming processing to data lakes. It is the foundation for creating reliable and performant data pipelines.
Key Features
- ACID Transactions: Ensures data consistency even with concurrent reads/writes.
- Time Travel: Allows querying historical states of data using versions or timestamps.
- Schema Enforcement and Evolution: Prevents schema mismatches and supports adding new fields.
- File Management: Handles small file compaction and data optimization.
Use Cases
- Building reliable and scalable data lakes.
- Enabling batch and streaming data ingestion pipelines.
- Supporting advanced analytics with guaranteed data consistency.
Example
Using Delta Lake to store raw and processed data for a machine learning pipeline:
from pyspark.sql import SparkSession
# Write data to Delta Lake
data = spark.range(0, 5)
data.write.format("delta").save("/mnt/delta-lake/raw-data")
2. Delta Table
Definition
A Delta Table is a logical representation of data stored in Delta Lake, enabling users to interact with the data as if it were in a database. You can perform operations like querying, updating, and merging using SQL or Spark APIs.
Key Features
- SQL Querying: Perform
SELECT,INSERT,UPDATE,DELETE, andMERGEoperations. - Integration with BI Tools: Use Delta Tables as datasets for analytics in tools like Power BI or Tableau.
- Schema Management: Automatically enforce schema on write.
Types of Delta Tables
- Managed Delta Table: Databricks manages the table metadata and data.
- External Delta Table: You manage the storage location, but Databricks maintains the table metadata.
Use Cases
- Querying processed data for reporting and analytics.
- Updating and merging data during ETL workflows.
Example
Creating and querying a Delta Table:
-- Create a managed Delta Table
CREATE TABLE delta_table
USING DELTA
AS SELECT * FROM parquet.`/mnt/data/raw-data/`;
-- Query Delta Table
SELECT * FROM delta_table WHERE value > 2;
3. Delta Live Table (DLT)
Definition
Delta Live Table (DLT) is a Databricks-managed service that automates the creation, deployment, and monitoring of data pipelines. It is built on Delta Lake and allows defining ETL workflows declaratively using SQL or Python.
Key Features
- Declarative Pipeline Definition: Define data transformations using simple SQL or Python.
- Auto-Managed Pipelines: Automatically handles infrastructure, dependencies, and table creation.
- Continuous Data Processing: Supports both batch and streaming data ingestion.
- Quality Rules: Built-in tools for data quality checks and monitoring.
Use Cases
- Automating ETL pipelines with minimal manual intervention.
- Real-time data processing and monitoring for streaming analytics.
- Simplifying pipeline maintenance with auto-updates and error handling.
Example
Creating a Delta Live Table pipeline with SQL:
-- Define a Delta Live Table pipeline
CREATE OR REFRESH STREAMING LIVE TABLE transformed_data
AS SELECT value, value * 10 AS value_times_ten
FROM STREAM(LIVE.raw_data);
-- Query Delta Live Table
SELECT * FROM LIVE.transformed_data;
Comparison
| Aspect | Delta Lake | Delta Table | Delta Live Table |
|---|---|---|---|
| Purpose | Storage layer for reliable data lakes. | Logical table for querying and managing data. | Managed service for automating data pipelines. |
| Key Features | ACID transactions, time travel, schema enforcement. | SQL querying, upserts, deletes, schema management. | Declarative pipelines, auto-deployment, monitoring. |
| Processing | Batch and streaming data storage. | Batch and streaming queries. | Batch and streaming data pipelines. |
| User Interaction | Used programmatically for data storage. | Queried via SQL or Spark APIs. | Defined via SQL or Python workflows. |
| Automation | Requires manual configuration. | Requires manual querying and updates. | Fully automated and managed by Databricks. |
How They Work Together
- Delta Lake is the foundation, storing raw and processed data.
- Delta Tables provide a structured interface for interacting with this data.
- Delta Live Tables build pipelines to process and transform raw data into Delta Tables automatically.
